What is a Brownfield Project?
The term “Legacy code” has many definitions, the most relatable IMHO is how Michael Feathers defines it in his book Working Effectively with Legacy Code. Any code that does not have tests is effectively legacy.
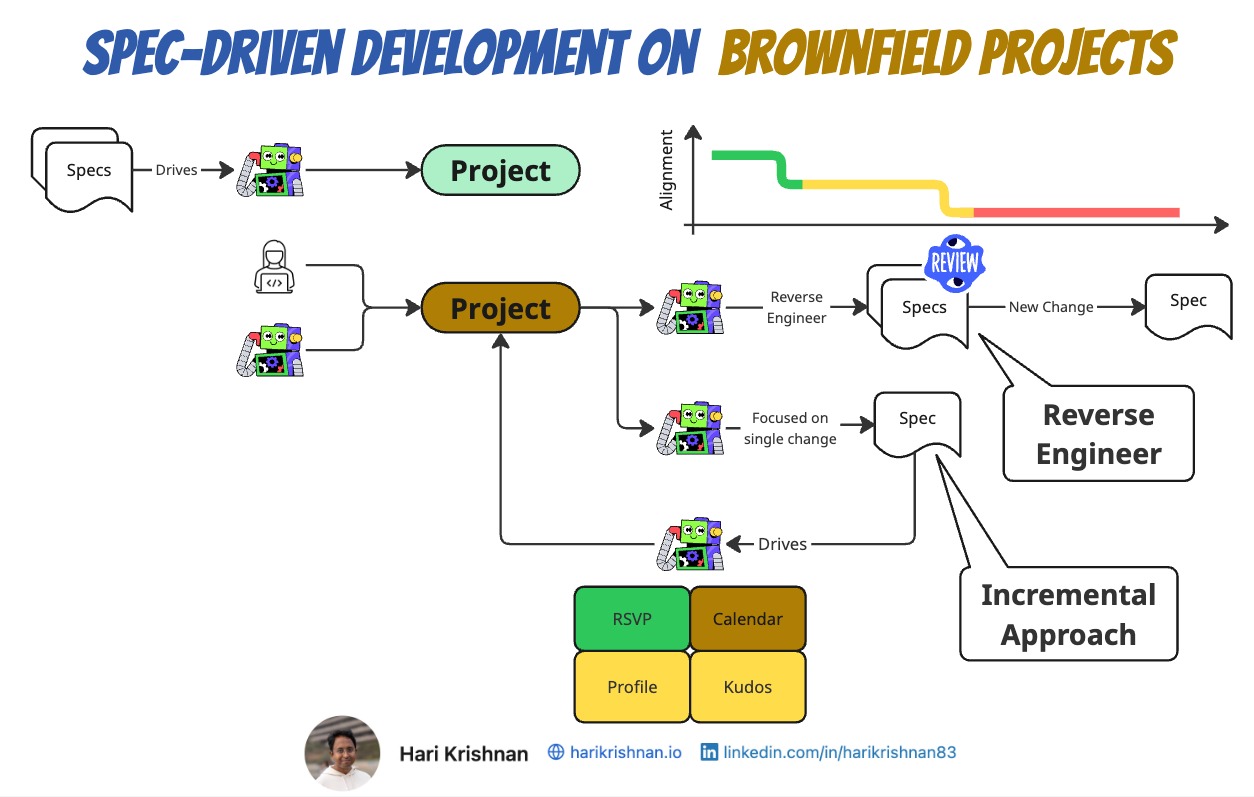
Similarly “Brownfield”, in the context of SDD, can be defined as projects that were not built based on specs. The only artifact that is available to us is the implementation or the code itself.
Can We Reverse-Engineer Specs?
In theory, we can reverse-engineer it. A quick way to achieve it is by using tools like repomix to pack the code into smaller sizes and give it to an LLM along with context of the SDD tool we are using. This can help generate the overall spec.
In practice, however, AI-generated specs are often inaccurate. The model doesn’t fully capture the original developer’s intent or the subtle nuances embedded in the code. The result is a spec that looks plausible on the surface but diverges from reality. This can’t be trusted as a foundation for future development.
The Issues with Reverse-Engineering
Reverse Engineering the spec itself can be quite involved. And even if we do, reviewing the specs may not be practical.
In the context of Test-Driven Development, when dealing with legacy code which does not have tests, should we start by writing all the tests first? That is not practical. In Feathers’ work in Working Effectively with Legacy Code the approach taken is largely to cover the area of code change with tests to first establish current behavior (characterization tests). Then we can test drive the remaining code.
Similarly it is a lot more practical to incrementally author specs for brownfield projects.
There is also the problem of alignment loss. A reverse-engineered spec is a derived artifact. When new features are developed against a misaligned spec, the risk of regressions and unintended side effects rises sharply, because the spec no longer reflects the real ground truth of the system.
Why Incremental is Better
The incremental approach focuses specs on a single, upcoming change rather than attempting to capture the whole codebase at once. Before making a modification, you author a spec for just that area — the change you are about to make. This is far more economical: the scope is bounded, the context is fresh, and the resulting spec accurately reflects intent.
Over time, this practice compounds. Each change leaves behind a spec that covers its slice of the system. As spec density grows in frequently touched areas, those sections start to behave like greenfield zones. The coverage builds naturally where it matters most.
For a deeper look at how this applies at scale, see my article on Enterprise Spec-Driven Development on InfoQ.
Brownfield Spec-Driven Development with OpenSpec
Use a Custom Profile and the Explore → Continue Workflow
When applying SDD to brownfield projects with OpenSpec, prefer using a custom OpenSpec profile over the default propose command. For more information on custom profiles, please see OpenSpec 1.2 release blog post.
The recommended workflow for brownfield is:
/opsx:explore— explore the change and understand the codebase before any spec is written- Review the exploration output
/opsx:continue(or fast-forward through artifacts) — progress through proposal, spec, design, and tasks one at a time
In brownfield projects reviewing aach artifact individually gives you more control over what gets generated thereby keeping the spec grounded in the real codebase.
Pass Codebase Context During Explore with Repomix MCP
During the explore phase, pass context about the existing codebase using Repomix MCP. This educates the AI on the brownfield codebase before spec writing begins, so the resulting artifacts reflect the actual system rather than assumptions.
Example command:
/opsx:explore I would like to remove the maybe option in RSVP, use repomix mcp to understand existing code
Repomix packages your codebase into a format the AI can consume directly, giving the explore phase accurate grounding in what already exists.
For large codebases, tools like Repomix are especially helpful in managing context window usage.
Conclusion
Incremental approach gives you control, accuracy, and progressively growing coverage, without requiring a big upfront investment in reverse-engineering specs that may not hold up. You start where the work is, build specs that reflect genuine intent, and let the brownfield gradually transform over time.
To see this in action, watch the video below. It walks through a real-world example demonstrating how to use RepoMix to package an existing codebase, feed it to an AI model for analysis, and then author a targeted spec for the next change.